Intro
Over spring break, I joined a team to try for AlphaPilot, an autonomous drone racing competition. There are 3 tests for this. The first test is a video talking about the team and why we are competing, the second test is a vision challenge where you need to identify gates with vision, and the third test is a autonomous drone control challenge. The third test is not due yet, but the 2nd test’s due date is passed. This is the primary test I worked on. Here are some examples of the images in the dataset.

We needed to identify the locations of the corners of the gate.

They gave us around 9000 images for training, with the corner locations as labels. Their labels also had some errors, which was not intentional since they apparently corrected the errors later.
Our First Attempt
Our first attempt was using deep learning and convolutional neural networks. This was my first time ever using convolutional neural networks or deep networks (I have rarely ever gone above ~20 layers before this).
I first tried to create my own model, which didn’t work too well to say the least. I copied a simple set of layers from a random tutorial and changed a few things.
Note that this was the heavily modified version, after the original didn’t work and we tried unsuccessfully to change various parts. So there’s some weird things like a leaky relu with a leak of 0.3 (which is very high). The output is the coordinates of the 4 points. I made many modifications to this model (adding and removing layers, changing batch size, etc). Regardless of what I did, even though it would slowly train, the network started at a VERY high loss. This picture is kind of funny, it shows where the neural network was predicting locations after training for a short time.
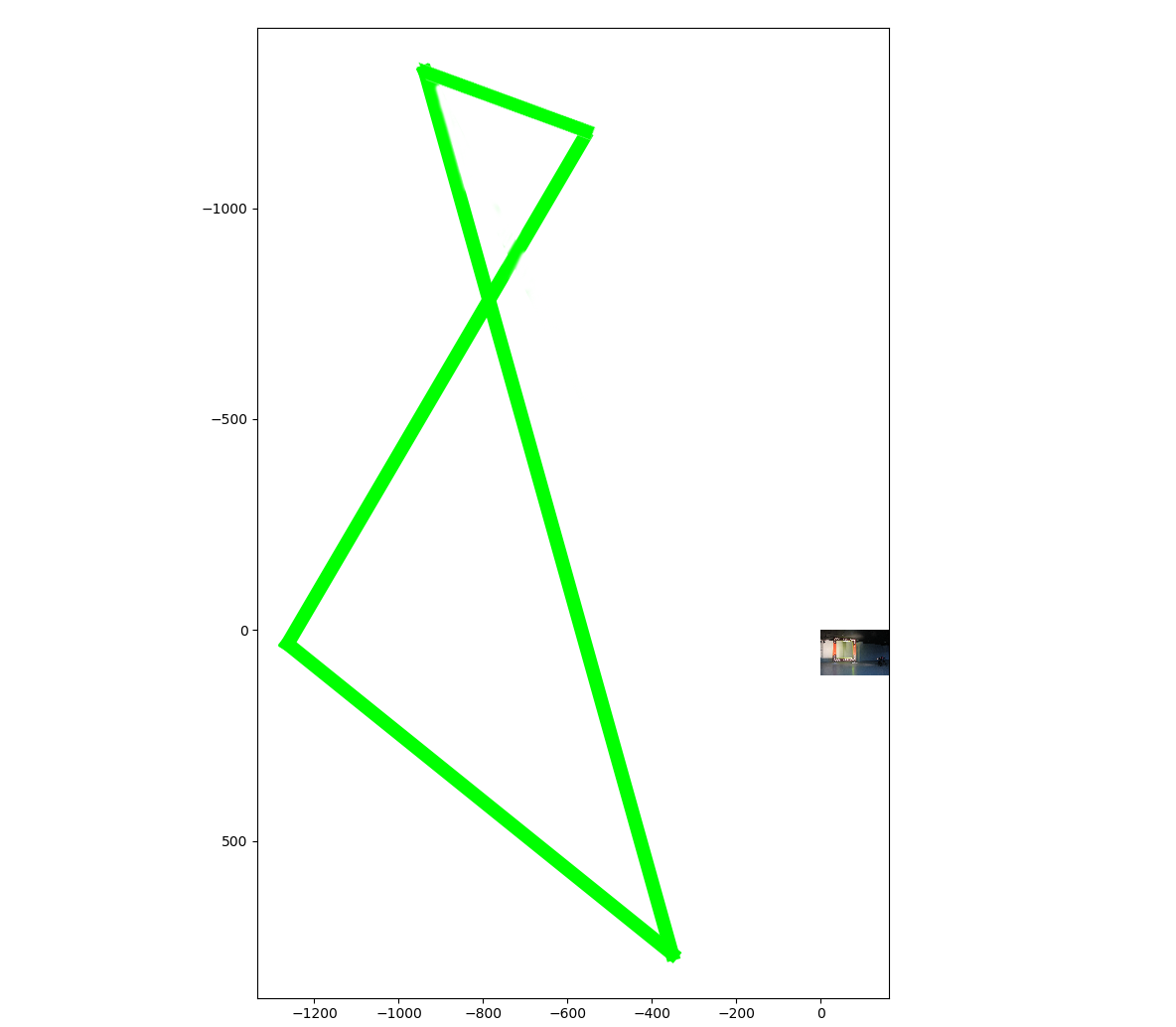
If you are wondering what is going on here, the neural network was predicting coordinates that were nowhere near correct, and were in fact entirely outside of the image. This led to one of my biggest lessons from this competition so far: Always transfer learn when possible.
Transfer Learning
Transfer learning is when you take a neural network that is pretrained on another dataset, and start training it on your dataset from its current weights, as opposed to training it entirely from the beginning (random weights) on your dataset.
Although my network was terribly designed (I just guessed at it with little prior knowledge/experience on what works), I think the real reason why it had huge loss and results outside of the image’s region was due to it being trained from random weights, without transfer learning. Without transfer learning, the network is starting from a completely random location that is likely to be very far away from the minimum. With transfer learning, the network will already be 90% trained, and close to the minimum.
Here are two advantages of transfer learning that I know of right now:
- The learned features are useful for other datasets. For example, an edge detection filter found on one dataset is general enough to be useful on other datasets. Because of this, the minimums of the network for different datasets are likely to be close together, lowering learning time.
- Transfer learning lowers the chance of overfitting and lowers the amount of data needed. You can train a network on a really large dataset, such as a public one with millions of images, and then train it on your smaller dataset. This will work because it is already close to the minimum as explained before.
These two advantages were essential for our situation. For advantage 1, we had one GPU, and training the network from random weights could have taken weeks.
For advantage 2, we only had 9000 images and a single object. Its a decent amount of images but it is not millions of images. Without transfer learning, there was the potential for overfitting. With transfer learning, we could take a model that was trained on a massive dataset, which will be close to the right weights, and then train the rest of the way to the minimum loss with the 9000 images.
So I had to look for a trained model to use, and abandon the original model. I am still glad I tried to make my own, because I learned about convolution layers, dropout, etc. I also realized that the systems used for object detection were much more complex than I thought. Neural networks are not as good at detecting position within an image without modification, so various strategies have to be used to give the neural networks parts of an image at a time (YOLO, R-CNN, Fast R-CNN, Faster R-CNN, etc.).
Implementing RetinaNet, Learning Docker
After struggling for many hours to get tensorflow-gpu working, we tried using a Docker image instead, and it worked instantly. In the process, we learned how to use Docker, which is great since it seems extremely useful and I personally hate dealing with installation issues, which Docker gets right past.
We ended up trying a RetinaNet model from this repository. We easily set up our dataset up to work with it by following the instructions, and after a small amount of training, we got this:

The network outputs two corners of a box, and so we drew a line between the predicted corners to visualize it. The other two corners are not accurate because this method has the same problem as before: we need all 4 corners, not a rectangle with vertical and horizontal sides. We trained it for much longer (probably around 10–20 hours) …and then deleted it by accident since we were still learning to use docker. Oh well. We decided to think up solutions for the 4 corners problem before trying to train again.
Abandoning CNNs and Switching To OpenCV
We considered rotating the image and checking the corners again, adding the other two corners as a second object, and other things but ended not trying any of these things because we moved to using purely OpenCV. The reasons for abandoning neural networks were
- Run time was one of the metrics that decided our leaderboard score, and we thought a pure opencv method would be faster.
- We weren’t sure how long it would take to find a way to get the four corners.
- We were worried about the mislabeled data, and there was too little time left by the time they corrected their labels.
- The training time was too long, taking 1–4 hours to get something that showed the potential of a method and an unknown number of hours to get to the minimum. We never actually fully trained a single network, the highest we did was ~20 hours (the deleted one), and it still wasn’t fully trained. We only had a week when we started, and by the time we stopped we only had ~2 days.
So we went with OpenCV
Update: Since the qualifications are done, I will probably eventually make a post about our OpenCV method, or add it to this one. We did not complete test 3 due to lack of time. Spring Break ended for me, and everyone else on the team was busy due to school, jobs, and travel.